TL;DR: Even though RL feels kind of quiet nowadays outside of RLHF, it still blows my mind that agents can learn purely from experience — no labels, just trial and error. It’s messy, unstable, and hard to debug, but there’s something so raw and human-like about it. That’s what I’m chasing by building AlphaTicTacToe from scratch.
[UPDATE]: The repsitory is completed and the corresponding PyTorch implementation is available here.
Thoughts on RL
Recently, I don’t see reinforcement learning being used that much outside of things like RLHF. Before LLMs took off, RL was the frontier and showed us how powerful scaling up machine learning problems can be.
RL is one of those fields that feels like magic when you first encounter it. Give an agent some rewards, throw it into an environment, and somehow, over time, it figures out how to win by minimizing loss.
Behind that magic is a rigorous and delicate balance between trial and error learning, exploration, value estimation, and function approximation.
What’s always fascinated me about reinforcement learning is how well it learns without labels. Learning purely from experience helps the model come up with it’s own features in a cool way, since it finds a structure in space that minimizes loss.
In some ways RL feels way more human-like. But learning from no labels and setting up the environment makes it hard to debug, unstable to train, and overly sensitive to design decisions. By designing and building AlphaTicTacToe I hope to learn more about the training and learning process in reinforcment learning.

Why TicTacToe? How does it compare to Go?
TicTacToe might seem like a joke compared to Go, and it kind of is. Go has more board configurations than atoms in the universe whereas TicTacToe has just 765 unique board states. But that simplicity is what I want to take advantage of.
AlphaGo combined deep learning, reinforcement learning, and tree search to beat world champions. My goal wasn’t to replicate that scale, it was to replicate the ideas. TicTacToe gives me a controlled, fully observable world where I can implement:
- Self-play training
- A policy network
- A value network
- A touch of MCTS
In other words, a tiny lab to test the same techniques that powered AlphaGo and AlphaZero but in minutes instead of months.
Core concepts we’ll use
Before we dive into architecture and code, here are the main concepts this project draws from:
Policy Network
A neural net that maps board states → probabilities over next moves. This is how the agent decides what to do given the current input.
Here’s a simple example for our case:
- Policy Network input: Current board (a 3x3 grid encoded as a 1D tensor)
- Policy Network output: Probability distribution over all 9 positions
If we had a 3x3 board like
[ 0, 1, -1,
0, -1, 1,
1, 0, 0]
where
- 1 = our move (X)
- -1 = opponent move (O)
- 0 = empty cell
Our policy network would return
[0.05, 0.01, 0.00, 0.20, 0.00, 0.01, 0.40, 0.03, 0.30]
which is a probability distribution over the whole input (what we usually see after a softmax). The above means that the network thinks
- Move 6 (index 6) is most likely ot be the best (40% chance)
- Move 8 is the next best (30% chance)
- Moves like 1, 2, 4, 5, 6 are either illegal (the board isn’t empty there) or bad (game losing moves) hence the 0 - 0.01%
The agent would sample from this distribution or choose the argmax depending on the setting. Here’s an NLP analogy: does this kind of remind you of picking the right token after scaled attention (argmax, beam search, etc.)? It’s the same concept but now applied to moves in a game instead of picking the next best token.
Value Network
This is another neural net that maps board states → estimated outcome (win/loss/draw). It helps the agent understand which states are “good” and which states are “bad” (moves that will most likely to hurt your chances of winning).
Think of this like asking:
“If I’m in this position and play optimally from here, how likely am I to win?”
Let’s dive deeper
- Value Network input: Current board (a 3x3 grid encoded as a tensor, just like what we saw above)
- Value Network output: A single scalar value between -1 and 1 describing winning likelihood of winning
The scalar result of a value network is actually pretty easy to understand. A value of 1.0 means guaranteed win, a vaue of -1.0 means we’re definitely going to lose, and 0.0 means a draw or unclear outcome.
These two (policy and value networks) work together really well. We can look at them like the following.
If you’re standing at a fork in the road, the policy network says “turn left, I think it leads to the best destination” and the value network says “this spot you’re in right now? I’d rate it a 7/10. Not bad but not amazing either.” You would know to go left because of what your policy network says and given the fact that your value network thinks you can get to a better position (you want to get to a 10, not a 7).
This combination of knowing what to choose and instantly evaluating your current state helps agents look ahead smartly like humans do when thinking “if I go here, what’s likely to happen?”
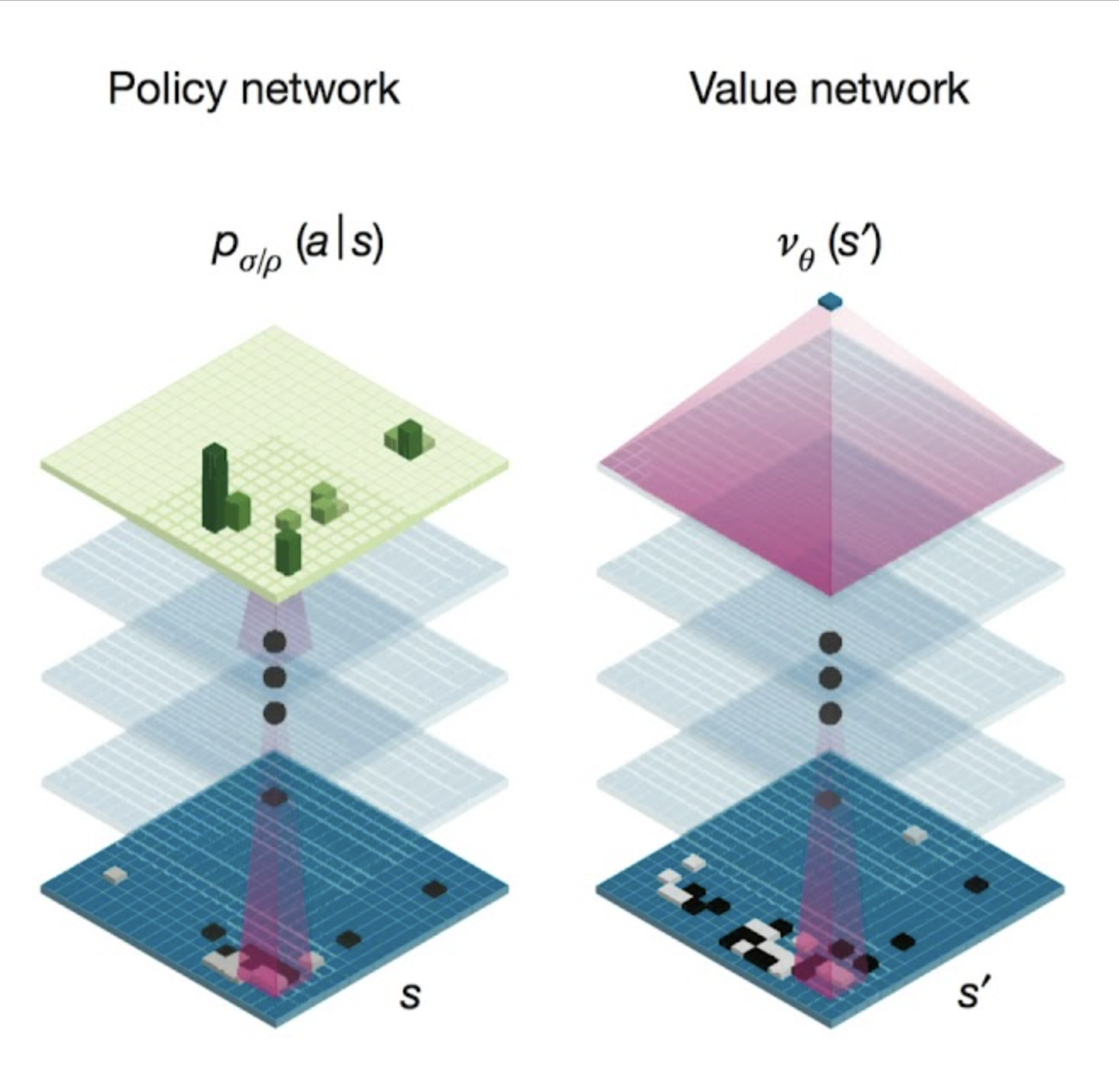
This picture shows how the policy network and value network work in Go, but the same concept applies in tic-tac-toe.
Self-Play (for TicTacToeZero)
In self play, the agent learns by playing against itself, without any human data. This is what made AlphaZero groundbreaking because it kind of “taught itself the game”. I’ll go more into this when we prepare for training.
Reward Signal
This is super simple. For every game, we can assign
- +1 for a win
- -1 for a loss
- 0 for a draw
This reward signal is sparse and very delayed (only received at the end of the game) but it encodes everything that matters (win, lose, draw).
Though this is such a weak signal, the agent learns a lot through self-play, MCTS, and policy/value networks. This teaches the agent to evaluate board states and select promising moves, even when intermediate rewards aren’t available.
For these games:
- Winning is the only thing that matters
- MCTS provides intermediate guidance via simulation
- The networks generalize from outcomes to board positions
You don’t need dense rewards if your agent is powerful enough to learn from sparse ones.
Exploration Strategy
Early on, the agent needs randomness (like ε-greedy) to discover better moves before we move on to doing MCTS (Monte Carlo Tree Search, more on this later). This randomness counts as exploration noise and is crucial early in training.
In the beginning,
- Your networks are terrible (random weights)
- Terrible networks won’t explore less obvious (but potentially better) strategies
You end up in a toxic feedback loop:
Bad network → bad MCTS → bad self-play → no learning
With ε-greedy, you pick a random move instead of the best one with probability ε. This forces the agent to try moves that currently look suboptimal, but might actually
- Be super helpful down the line
- Help MCTS explore deeper, richer branches of the tree
- Expose the neural net to more diverse set of board states
To use a chess analogy: this is like giving the agent a chance to learn castling. At first, it looks like a wasted move. But over time, the agent realizes it’s actually super powerful for long-term king safety and control.
Monte Carlo Tree Search (MCTS)
I’ve been touching on MCTS a lot but haven’t explained it well yet. Here’s a proper breakdown.
MCTS is a search algorithm that helps an agent choose the best move by running lots of simulations, keeping track of which actions led to wins, and gradually growing a search tree based on experience, not hardcoded rules. Think of it as the scalable alternative to Q-tables used in tabular RL — but for massive action spaces.
The core idea is:
- From the current board, simulate random (or guided) games to the end
- Record which moves led to wins more often
- Keep exploring promising branches of the tree
Over time, we form a biased tree that favors strong moves.
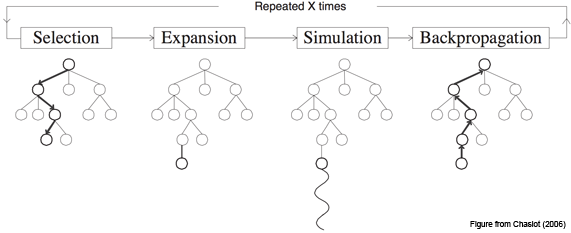
By repeating these steps thousands of times, MCTS builds a tree that implicitly “learns” which branches are worth pursuing — without ever training a model.
However, in AlphaZero, MCTS is used not just to pick moves, but to generate training data for the neural networks as well.
Let’s take a look at one whole MCTS loop.
- Selection
We start at the root (current board), and move down the tree by picking the most promising child using something like the UCB (Upper Confidence Bound) formula.
def select(node):
while node.is_fully_expanded():
node = max(node.children, key=ucb_score)
return node
def ucb_score(child):
# ucb1: exploitation + exploration
C = 1.4 # exploration constant
return (child.wins / child.visits) + C * math.sqrt(math.log(child.parent.visits) / child.visits)
- Expansion When you reach a node that isn’t fully explored, try a new move from that state and add a child node.
def expand(node):
untried_moves = node.get_untried_moves()
move = random.choice(untried_moves)
next_state = node.state.play(move)
child_node = TreeNode(state=next_state, parent=node, move=move)
node.children.append(child_node)
return child_node
- Simulation (Rollout) From that child node, play random moves until the game ends.
def simulate(state):
current_state = state.clone()
while not current_state.is_terminal():
move = random.choice(current_state.get_legal_moves())
current_state = current_state.play(move)
return current_state.get_result() # +1, 0, or -1
- Backpropagation
Propagate the result up the tree, updating the win/visit stats for every node along the way. This is not backprop in the regular sense - there’s no gradients, no weight updates, no chain rule. We’re just logging outcomes like a scoreboard. This is enough for us because MCTS just needs to show us viable paths.
def backpropagate(node, result):
while node is not None:
node.visits += 1
node.wins += result
result *= -1 # flip result for opponent's perspective
node = node.parent
These 4 steps combined become one loop (or “epoch” if you want to think about it in more of a DL sense). Repeating this thousands of times and we end up with a smart tree that recommends the best next move. This essentially becomes the “brain” of the whole model.
Here’s what it looks like put together
def mcts_search(root, num_simulations):
for _ in range(num_simulations):
node = select(root)
child = expand(node)
result = simulate(child.state)
backpropagate(child, result)
return max(root.children, key=lambda c: c.visits).move
not too bad right?
Run this thousands of times and you get a smart tree that recommends the best next move based on experience, not brute force. This becomes the agent’s “thinking loop.”
In Go, there are ~10^170 board states, making brute force search absolutely useless. MCTS changed the game by allowing us to selectively explore only promising lines, guided by past outcomes instead of expanding every possible branch like in BFS.
In TicTacToe, the board is tiny. We can do a full-depth BFS style search if we reallly wanted to. I still wanted to see if I could use MCTS + neural networks in this smaller world to learn like AlphaGo did, instead of hardcoding perfect moves with exhaustive search algorithms.
Because of how different Go and TicTacToe are, I’ll have to use a differenet version of MCTS.
- Instead of a deep tree, I ran 50 simulations per move.
- I used random rollouts (no value network at first)
This is definitley still overkill for TicTacToe (which can be done with an exhaustive search) but I wanted to model a network that could think and reason like AlphaGo on a smaller scale.
Design Choices for TicTacToe
TicTacToe is very simple but designing a learning agent still means making real decisions around how to represent the game, structure the model, and define the environment. Here’s how I approached it
State Representation
I touched on this earlier - a simple 9 element 1D tensor works well here in my opinion.
[ 0, 1, -1,
0, -1, 1,
1, 0, 0]
When I was thinking about different representations, ChatGPT recommended me to use one-hot encoding (3 channels: player, opponent, empty) but I wanted to keep this as simple as possible since the board is already tiny.
Action Space
There are 9 possible moves (indexes 0-8) where each corresponds to placing your symbol in one of the 9 cells.
- If the cell is already occupied → the move is illegal
- Policy network gives us a probability distribution over 9 cells
- During argmax (or sampling) selection, we mask the illegal moves so the agent doesn’t try to play in filled spaces
This way, the agent doesn’t get punished for illegal moves, it just learns not to choose them with masking.
Network Architecture
Both the policy network and the value network would become small MLPs (multi-layer perceptrons).
Policy Network
nn.Sequential(
nn.Linear(9, 64),
nn.ReLU(),
nn.Linear(64, 9) # raw logits → softmax
)
Let’s try to make sense of the hidden layer sizes. We first have an input of 9 because our input tensor is of size (9,) based on what we decided earlier and only has values of 1, -1, or 0.
The hidden layer size is 64. I chose this number as a sweet spot. It’s large enough to allow the network to learn useful patterns and combinations but small enough to avoid overfitting or unnecessary complexity for such a tiny input space.
Applying a ReLU gives us non linearity instead of just linear transformations.
We end with squeezing it back down to an output of 9. The resulting 9 logits are going to be your probabilities as we talked about that the policy network return, one per board cell.
The policy network’s job is simple: take in the current board and return a probability distribution over all 9 moves.
Value Network
nn.Sequential(
nn.Linear(9, 64),
nn.ReLU(),
nn.Linear(64, 1), # scalar value
nn.Tanh() # outputs belong to [-1, 1] (tanh applied on resulting logit for "squashing" to the -1, 1 range)
)
Just like the policy network, we have an input size of 9 and I still went with 64 as a sweet spot. The main change is the last two lines.
Our output layer is now just a single scalar value that estimates how favorable the current state is for the agent. This final output is then passed through a tanh squeezing it into the range [-1, 1] (as explained before). +1 would be a very confident win and -1 would be a certain loss.
This output is used to help guide MCTS and inform learning. It acts like a learned evaluation function that replaces brute-force rollout results.
The value network’s job is simpler: take in the current board and return a score for how likely you think this will win the game in the range [-1, 1] (tanh helps with this).
Game Logic
Before we can train an agent to play TicTacToe, we need to build the environment it lives in - the rules, state transitions, and reward mechanics. Here’s how I structured the game engine that powers both self-play and MCTS.
Applying Moves
Each player takes turns selecting a move (an index from 0 to 8). We check if the move is legal and update the board accordingly.
def apply_move(self, move):
if self.board[move] != 0:
raise ValueError("Illegal move!")
self.board[move] = self.current_player
self.current_player *= -1 # switch turns
Terminal Check
After every move I check for a win, loss, or draw. If the game is over, I return the final result
def check_winner(self):
winning_lines = [
[0, 1, 2], [3, 4, 5], [6, 7, 8], # rows
[0, 3, 6], [1, 4, 7], [2, 5, 8], # cols
[0, 4, 8], [2, 4, 6] # diagonals
]
for line in winning_lines:
values = [self.board[i] for i in line]
if sum(values) == 3:
return 1 # X wins
elif sum(values) == -3:
return -1 # O wins
if 0 not in self.board:
return 0 # Draw
return None # Game continues
Resetting the game
Each new game starts with a clean board and the first player to move
def reset(self):
self.board = [0] * 9
self.current_player = 1
This reset function is essential for:
- Self-play, where each game is an independent episode
- Training loops, where consistency across episodes matters
Without resetting, the leftover board state or player turn bugs could corrupt learning.
Cloning for MCTS
MCTS doesn’t need to reset the board, it needs to duplicate the current game state to run thousands of rollouts from it.
def clone(self):
cloned = TicTacToe()
cloned.board = self.board[:]
cloned.current_player = self.current_player
return cloned
Between .reset() and .clone() we’ve got a clean way to simulate and learn without state leaks or bugs.
Integration with Agent
At each step
-
The agent observes the current board state
-
It runs MCTS, using the policy network to guide exploration
-
MCTS outputs a move distribution (based on visit counts)
-
The agent samples a move from that distribution (or just takes argmax)
-
The selected move is applied to the board
-
The tuple
(state, move_probs, final_result)is saved for training
Here’s what I optimized for:
- Keeping everything small, fast, and interpretable
- Using self-play, policy/value, and MCTS to mimic AlphaGo logic
- Letting the agent learn from scratch rather than relying on hardcoded strategies
Training the Agent
There are two main paradigms for training a game playing agent like this:
- Learn via human gameplay (supervised learning)
- Learn from scratch via self-play (reinforcement learning)
The first is what AlphaGo did and the second is what AlphaZero did.
In this project, I chose to go with self-play. It’s slower and more complex than imitation learning, but it gives me a more scalable setup, an agent that can discover novel strategies on its own, and a deeper understanding of how learning emerges from interaction.
When playing games against itself, for each move it makes during a game, we store:
- The current board state
- The move distribution from MCTS (how often each move was visited)
- The final result of the game (win/loss/draw)
This gives us training examples in the form:
(state, mcts_probs, final_result)
and we then batch these to become
(batch_size, state, mcts_probs, final_result)
We can feed this data into a trianing loop after generating a batch of games. We train both the policy network and the value network using gradient descent.
for epoch in range(num_epochs):
for batch in replay_buffer:
policy_pred = policy_net(state)
value_pred = value_net(state)
policy_loss = cross_entropy(policy_pred, mcts_probs)
value_loss = mse_loss(value_pred, final_result)
loss = policy_loss + value_loss
loss.backward()
optimizer.step()
In my opinion, this is honestly kind of straightforward. Predict policy, predict value, calculate loss with cross entropy & mse and update your weights.
The overall loop continues to:
- Generate self-play games
- Batch data from those games
- Train on that data
- Update the policy and value networks
- Repeat
Over time, the agent improves not by memorizing moves but by learning which states are promising and which moves are strong, all from experience.
Before we finish up this section I want to touch on 2 things: the loss functions for policy_loss and value_loss.
In the value network we are predicting a single number at the end. This screams regression because we want the model to fit it’s prediction to a certain range. Using MSE encourages our predictions to be numerically close to the actual result.
For the policy loss, we are not predicting the correct move - we are trying to predict a probability distribution over 9 moves. The target is also a distribution, it’s the one generated by MCTS.
Since we’re doing distribution matching, cross-entropy is the standard for that.
If we tried using MSE here instead, it would try to numerically match each probability. On the other hand, cross-entropy measures how surprised your prediction is by the true distribution.
The target distribution comes from MCTS visit counts, reflecting which moves were explored the most during search. Instead of learning how to predict “one correct move”, the policy network is learning to imitate the move distribution that MCTS created.
Did it work?
I haven’t fully coded and trained the agent yet, but we have everything so far to go ahead and get started.
There are some clear signs that we can see to know if the model is training and generalizing well.
- From random to strategic
At first, the agent will make dumb, random moves. Over time, through self-play and training, I expect it to converge toward winning strategies like blocking opponents, going for forks, and always taking center if possible.
- Policy get sharper
The policy network should start off nearly uniform but as it trains on MCTS-guided targets, its output should begin concentrating around stronger moves and weaker moves should tend towards 0. This would match what an optimal player would do.
- Value network improves intuition
We expect the value network to be very noisy early on. With enough games however, it should begin to accurately assign high scores to strong positions (like 2 in a row with an open third) and low scores to losing ones (like when opponent has 2 in a row and has a chance to close in).
- Performance Metrics
One implemented, I’d like to track:
- Win rate vs. random agent
- Win rate vs. greedy agent
- Value estimation error (MSE)
- Policy prediction accuracy (Cross-Entropy)
This section wouldn’t be about flexing our results but rather about setting the expection. If everything above is done right, the model should learn to play well entirely from scratch.
These would be also be fun to track but a little harder to implement:
- % of times a fatal move is played (i.e., a move that directly allows the opponent to win on the next turn)
- % of games where agent creates a fork (shows strategic depth because forks are subtle and strong moves in TicTacToe)
- Average branching factor explored during MCTS (How many child nodes are explored on average — reflects how focused the agent’s search is)
Conclusion & Further thoughts
Let’s step back and look at what we have.
- We built a clean TicTacToe environment from scratch for agents to play in.
- Designed an agent that could play the game and make decisions.
- Equipped it with a basic Monte Carlo Tree Search engine.
- Let two clones of the agent play thousands of games against each other.
- Used the data from self-play to train a policy and a value network.
- Watched our agent go from clueless to competent — learning how to win and stay sharp entirely through experience, without a single labeled example.
I’ll wrap up by nailing how the self-play / training / inference pipelines work.
During self-play
- Agent observes current board state
s - Run MCTS from
sto choose a move
- MCTS uses the policy network to guide exploration
- MCTS optionally usese the value netwrok to evaluate leaf states
- MCTS performs N simulations, builds a search tree, and collects visit counts for each move
- Get move probabilities from MCTS
- Argmax or sample from that move distribution to pick your action
- Play the move and update the game state
- Store tuple
(state, move_probs, final_result)for training later - Repeat until game ends
- If game won: assign +1 to every state
- If game lost: assign -1 to every state
- If game draw: assign 0 to every state
We assign this same value to every state because the value network is trained to predict “what is the expected outcome from this board state, assuming optimal play?” Also, all those states sequentially led to the win and that’s why they all get the same label.
During training
After a batch of self-play games you have a dataset
(batch_size, state, mcts_probs, game_result)
For each training example, we feed:
- Input: board state
- Target for policy network: MCTS move probabilities
- Target for value network: final outcome of the game (1, 0, -1)
We feed in multiple batches at once (just like training any other model).
During inference
Once training is complete and our policy & value networks are strong, we can play games using them directly. There are two main options:
Option 1: MCTS + Networks
We continue using MCTS at inference, but now guided by the trained networks.
- The policy network initializes move priors at each node
- The value network replaces rollouts with learned estimates
This is exactly how AlphaZero plays: every move still runs simulations, but they’re smarter and faster.
Option 2: Policy Network only
In smaller environments like TicTacToe (or latency-sensitive apps), we can skip MCTS and just do:
move = argmax(policy_net(state))
This is less strategic but it’s extremely fast.
AlphaTicTacToe (and even AlphaGo) is essentially just MCTS but guided by deep learning (policy and value nets).
MCTS handles the planning (tree-based lookahead) and neural networks handle the learning generalize from past games.
If you think about it, there’s a lot of concepts shared between different fields within ML. MCTS guided by value & policy networks? That reminds me of tokens attending to others will generating text. Argmax or sampling from the probaility distribution after the policy network? Does that not remind you of beam search / argmax while generating text?
Coding it out
Whenever I get the time, I’m going to code this up and show the process, the agent getting better over time, and what struggles I had. Hopefully the next long weekend or whenever I have some time.