TL;DR: I built an agentic AI framework from scratch instead of relying on pre-made tools like AutoGPT or CrewAI. This post walks through designing the agent’s brain (LLM), memory (vector DBs + logs), tools (file system APIs), and control loop — then building a real File Cleanup Agent with dry-run prompts, scratchpad memory, error handling, and CoT reasoning. I also talk about scaling to multi-agent systems, sandboxing dangerous actions, and turning your agent into a production microservice.
The repsitory with the corresponding PyTorch implementation is available here.
Though agents are still early in their development, I really think that they bring the “artificial intelligence” to common people. If you really think about it, bots are the ones that actually will have the biggest effect on people’s day to day lives - that’s when AI goes from assistant to a tool with real value.
Online, I’ve seen a lot of boilerplate frameworks for using agents but I realized that unless I make one from scratch, I won’t fully understand what’s going on under the hood. I’ll start by designing and validating the agent first and then building
Designing an AI Agent
From doing all my research I’ve come to the conclusion that the current paradigm in agentic AI is hacking together a brain by making the core LLM act like one, and wiring up external tools to cover what it lacks.
Agent = autonomy + memory + tool use + goal orientation
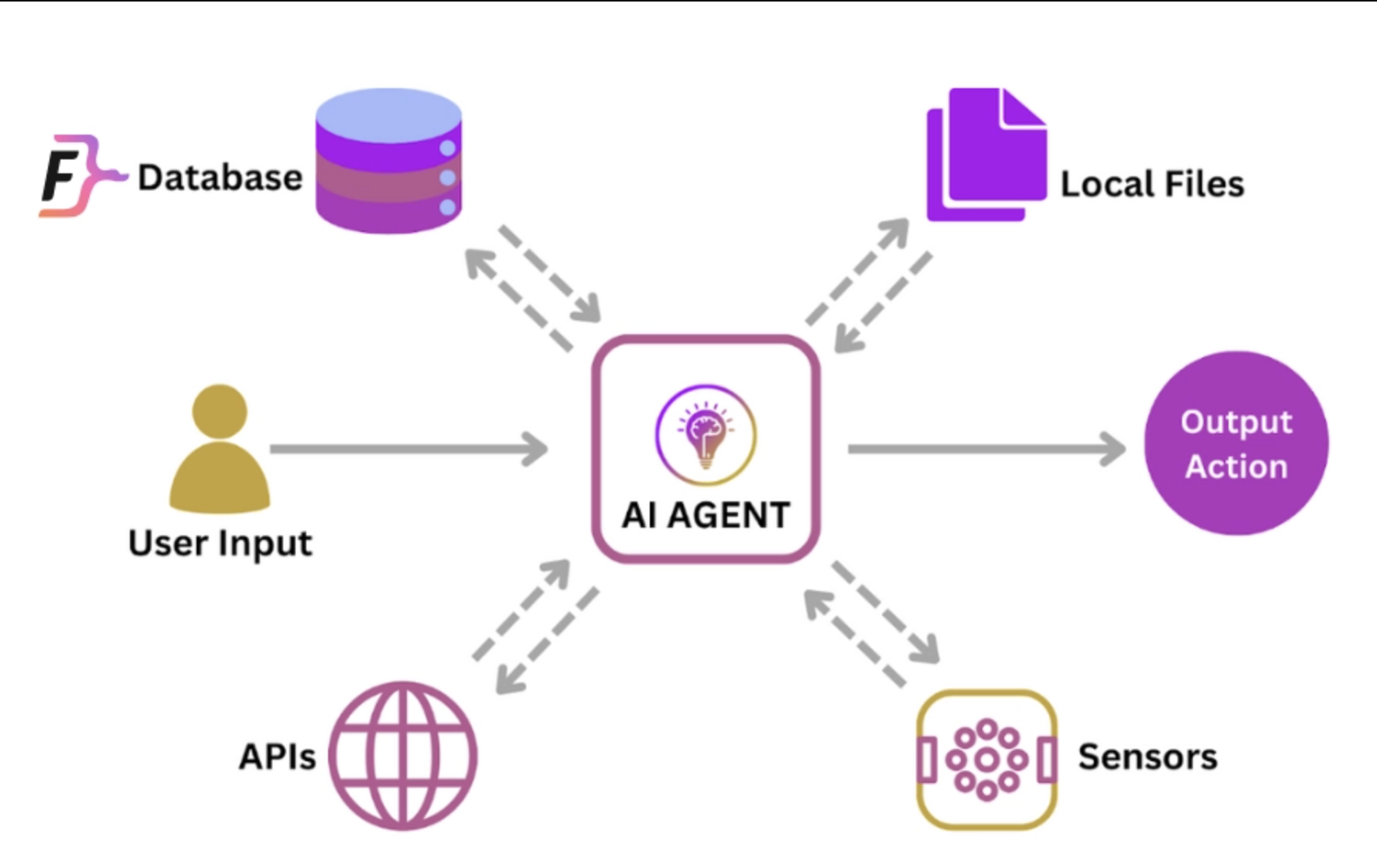
The LLM becomes the "brain" and everything else becomes APIs (not just web APIs but APIs to call external sensors, etc.) that the brain calls as depicted here.
The Brain of the Agent
We use the the LLM (GPT-4o, Claude, Mistral, etc.) as the reasoning core.
- Pro: It handles planning, language comprehension, tool selection, and decision making
- Con: Since it doesn’t have persistence, state, or memory it’s a stateless tool (the core reason why we need to attach more things to make this useful)
The Memory of the Agent
The statelessness of the LLM needs is tackled with tools like:
- Vector Databases (Pinecone, Weaviate, Chroma) for long term recall
- Scratchpads / prompts (ReAct chains or chain of thought) for short-term memory
- Logs / state tracking in files or databases
- Occassionally, self-reflection logs are inserted for iterative learning (kind of like telling the LLM what happened before and now reason from there)
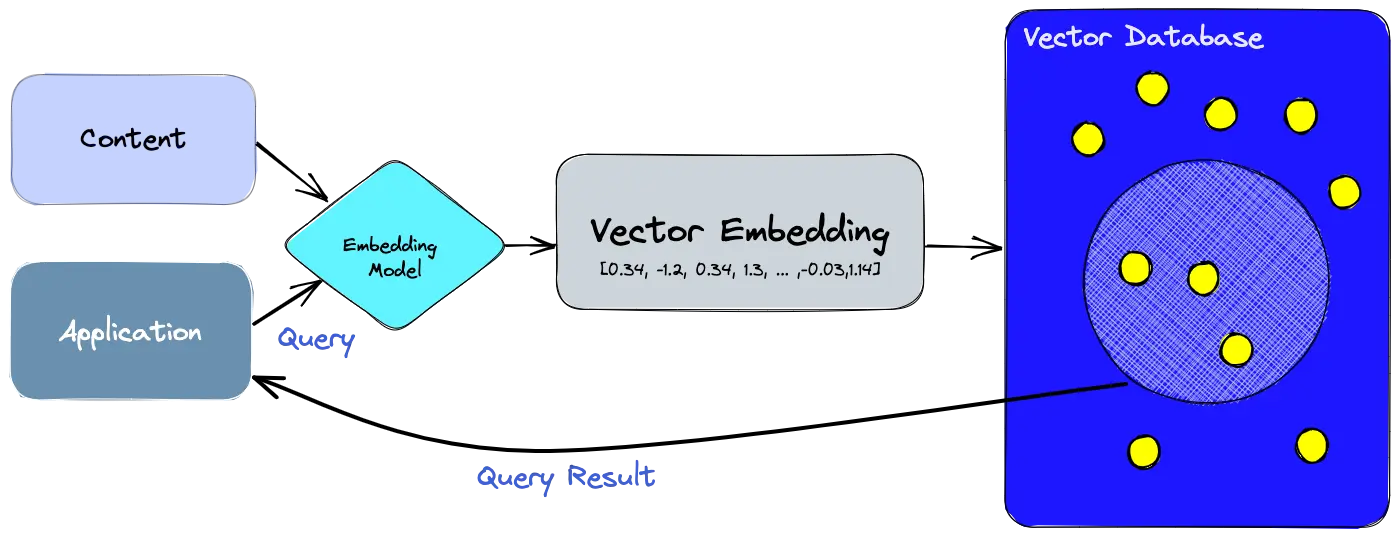
Vector memory lets agents retrieve semantically similar past interactions, even if phrased differently. This helps maintain context across tasks, boost reasoning accuracy, and reuse relevant info without hardcoding every rule.
The External Tools for the Agent (Body, Senses, Hands)
If you’ve read the famous Toolformer paper (Schick et. al, 2023) this should be pretty familiar - this paper lays the groundwork for LLMs to call other tools. In the case for the agent, we actually override this and instruct it like the following:
Hey LLM (GPT-4o/Claude/Mistral), here’s a scratchpad. If you think you need to use a tool, just write it like
Action: Search[BTC price OCT 2024]and we’ll do it for you.
If we look back at Toolformer, it might seem like we are doing something that modern architectures already take care of (like LLM writing Action: Search[something]) and execute. Agent models are not using that yet because we need special training data and gradient updates to the backbone of the model. The issue is that most models we use for agents are not open source (OpenAI, Anthropic) so we can’t retrain them and even with the open-source models we don’t have enough compute to go ahead and fine tune them. Doing it manually also just gives us more control over the external APIs that are going to be called.
Here’s how it would work in the real world:
-
LLM Thought: I need to calculate the revenue
-
Action:
call_python(price * quantity) -
Observation: $500
-
LLM Thought: Great, the revenue is $500. Let’s continue…
The Persistence for the Agent (Looping)
Every single step of the agent’s behavior has to be re-fed into the model — like a goldfish with no short-term memory unless you glue the past back in. This is where the context window comes in.
Most models have a token limit (ranging from 8K-128K tokens) where they store:
- All previous thoughts
- Past actions
- Tool outputs (observations)
- Any instructions or reflections
To make the LLM seem “alive” over time, we wrap it in a control loop. Tools like AutoGPT, BabyAGI, or CrewAI shine in doing just this: Plan, Act, Observe, Reflect, and Repeat.
An example loop could look like the following:
- Plan - LLM decides what subgoal or steps come next (“I need to look up product reviews”)
- Act - LLM decides which tool to use (
Search [iPhone 15 reviews]) - Observe - An external tool (web scraper / internal or external API) fetches results (“Top review says iPhone 15 battery life is amazing and great phone for the price.”)
- Reflect - LLM reflects on successes / failures (“LLM Thought: Good data, but I need more sources than just amazon.com”)
- Repeat - Feed everything above into the next prompt and continue.
This gives the illusion of memory and continuous reasoning. You can think of the agent’s memory as a human-readable version of an RNN hidden state; it evolves over time as the agent observes the world, makes decisions, and updates itself based on outcomes.
AutoGPT / CrewAI essentially package and orchestrate this. They:
- Keep track of agent memory (usually a simple list of dictionaries)
- Manage tool execution between LLM calls
- Let you define multi-agent systems where each agent has a role (kind of like kubernetes for agents)
In a sense these frameworks are the brain’s executive function. Here’s a side by side comparison of what I found online:
| Function | Real Brain | Agentic AI |
|---|---|---|
| Reasoning | Prefrontal cortex | LLM (GPT, Claude, etc.) |
| Memory | Hippocampus | Vector DB + prompt context |
| Acting on world | Motor cortex | Tools / API calls / web actions |
| Sensory input | Eyes, ears, etc. | Observations via tool outputs |
| Reflection | Meta-cognition | Reflexion-style re-prompts |
Before we dive into building, let’s do a recap of the tools we need.
Toolkit checklist
-
Foundation model – OpenAI GPT‑4o / Llama‑3 / Mixtral‑8x22B (brain)
-
Orchestration lib – AutoGPT / BabyAGI / CrewAI (optional orchestration engine if you don’t want to make a persistent loop)
-
Vector DB – Pinecone / Weaviate (recall & context)
-
Key–value memory store – Redis / DynamoDB (scratch‑pad state, explained below)
-
Planner / workflow engine – Python asyncio (better for simple agents) / Celery with RabbitMQ (better for complex agents)
-
Tool wrappers – OpenAI function‑calling / REST & gRPC / Playwright (the hands and feet of the agent)
-
Sandbox & security – Docker / network ACLs / per‑tool scopes (imagine letting the agent call
os.system("rm -rf /")at the root 😵) -
Observability – OpenTelemetry / Prometheus + Grafana (to monitor the metrics of the agent)
Now that we know which tools we are going to use, let’s start building our agent.
Building an AI Agent
1) Spinning up an Agent
A. Define the mission
This should be the overall high-level objective: we want a mission that can do tasks, nothing too complicated because I don’t have much compute / data but also not too simple that a non-agentic AI can easily handle as well (like check the weather in New York everyday at 9 PM).
Over time, success will be measured with how well it has completed this task.
Given the fact that I want reproducability and containerization, I wanted to go with a “File Cleanup Agent” - simple linux APIs but a pretty effective tool if you are like me and your /Documents is cluttered.
B. Enumerate action space
| Action | Description | Purpose for Agent | Linux Equivalent |
|---|---|---|---|
list_dir(path) |
Lists all files and folders in the target directory. | Scans current state of /Documents. |
ls -al path |
get_metadata(file) |
Retrieves file info like size, extension, last modified time. | Helps the agent make decisions based on recency, type, or size. | stat file or ls -lh file |
move_file(src, dst) |
Moves a file from one location to another. | Organizes cluttered files into categorized subfolders. | mv src dst |
delete_file(file) |
Deletes a file from the system. | Removes junk files (e.g., .tmp, .log, .DS_Store). |
rm file |
create_folder(path) |
Creates a new folder if it doesn’t exist. | Makes subfolders like /Documents/Images, /Documents/PDFs. |
mkdir -p path |
rename_file(old, new) |
Renames a file to a cleaner, structured name. | Fixes messy filenames like Screenshot 2023-12-01.png. |
mv old new |
read_file_head(file, n) |
Reads the first n lines of a file. |
Helps classify files (e.g., detect if it’s code, text notes). | head -n 10 file |
find_old_files(days) |
Finds files older than a given number of days. | Identifies stale data for deletion or archiving. | find . -type f -mtime +30 |
Optional Extensions (useful, not necessary for this case)
| Action | Why it’s Cool |
|---|---|
categorize_file(file) |
Uses LLM to classify file type: “image”, “code”, “invoice”, etc. |
open_file(file) |
Opens a file using the system default viewer. |
log_action(action) |
Appends an action to a cleanup log file. Good for transparency & rollbacks. |
C. Draft prompts
Now that we have the action space ready, we have to instruct the LLM to go ahead and use those tools. Since we are storing our calls / actions in a scratch pad and eventually going to call those exact actions after approvals, we would need the LLM to return the actions and memory state in a proper format every time. If your LLM is good enough, it should be able to understand these instructions and return in the proper format (a highly quantized model or an early gen open source model might give you issues here).
“Hey LLM, here’s your mission, here’s what you can do, and here’s the current file state. Now reason and return a sequence of actions.”
Here’s what a draft could look like in our case:
agent_prompt.txt
You are a File Cleanup Agent running inside a Docker container.
Your goal is to intelligently organize and clean the `/Documents` directory using a set of basic Linux-style file operations. Below, the function is listed and the corresponding linux command is in paranthesis.
Current more: dry run
---
Mission:
Organize the folder structure, archive old files, and delete junk (e.g., `.tmp`, `.log`, `.DS_Store`). Group files into meaningful subfolders like `/Documents/Images`, `/Documents/Finance`, etc.
---
Action Space:
Here are the only actions you are allowed to use:
- `list_dir(path)` → Lists all files/folders at the given path. (`ls -al path`)
- `get_metadata(file)` → Gets size, type, and timestamps. (`stat file`)
- `move_file(src, dst)` → Moves a file to a new location. (`mv src dst`)
- `delete_file(file)` → Deletes a file. (`rm file`)
- `create_folder(path)` → Makes a new folder. (`mkdir -p path`)
- `rename_file(old, new)` → Renames a file. (`mv old new`)
- `read_file_head(file, n)` → Reads the first n lines. (`head -n 10 file`)
- `find_old_files(days)` → Returns files older than a threshold. (`find . -type f -mtime +days`)
---
Current Directory Snapshot:
[
{ “name”: “Screenshot 2023-12-01.png”, “size”: “1.2MB”, “last_modified”: “2023-12-01” },
{ “name”: “Invoice_2022.pdf”, “size”: “345KB”, “last_modified”: “2022-04-10” },
{ “name”: “notes.txt”, “size”: “9KB”, “last_modified”: “2024-11-02” },
{ “name”: “temp_file.tmp”, “size”: “3KB”, “last_modified”: “2021-09-01” }
]
---
Instructions:
Using only the allowed actions, return a list of **python-style function calls** that clean up the `/Documents` folder based on file type, age, or naming patterns.
Your output should be a list like:
[
create_folder(“Images”),
move_file(“Screenshot 2023-12-01.png”, “Images/”),
create_folder(“Finance”),
move_file(“Invoice_2022.pdf”, “Finance/”),
delete_file(“temp_file.tmp”)
]
Only include actions that are necessary — no redundant calls.
---
If you're in a "dry run" mode, prefix each action with a comment explaining why you're doing it.
Though a good draft prompt is essentially like writing a nice document, it is critical to the success of the agent. This is essentially the overall context for the LLM.
D. Control loop
The loop is your core agent driver. It does the following
- Gets the current environment state
- Calls the LLM to decide actions
- Parses & executes those actions
- Loops or exits
Here’s python pseudocode that will simulate a loop -
main.py
def agent_loop():
while True:
# get current file system state
state = list_dir("/Documents")
metadata = [get_metadata(f) for f in state]
# feed state + mission into the LLM prompt
plan = generate_plan_from_llm(metadata) # uses your prompt from earlier
# parse LLM response
actions = parse_actions(plan)
# execute actions one-by-one
for action in actions:
try:
execute(action)
except Exception as e:
log_error(action, e)
# break or wait
if is_cleanup_complete():
break
time.sleep(60) # optional: run every 1 min
utils.py
def list_dir(path):
return os.listdir(path)
def get_metadata(file):
try:
stats = os.stat(file_path)
return {
"path": file_path,
"size": stats.st_size,
"extension": os.path.splitext(file_path)[1],
"created": datetime.fromtimestamp(stats.st_ctime).isoformat(),
"modified": datetime.fromtimestamp(stats.st_mtime).isoformat()
}
except Exception as e:
return {"path": file_path, "error": str(e)}
def generate_plan_from_llm(state_metadata):
return openai.ChatCompletion(...) # LLM call with your prompt + current state
def parse_actions(llm_output):
return ast.literal_eval(llm_output.strip()) # parse output into list of actions
def execute(action):
if action.startswith("move_file"):
args = eval(action.replace("move_file", ""))
move_file(*args)
def move_file(src, dst):
os.makedirs(os.path.dirname(dst), exist_ok=True)
shutil.move(src, dst)
def is_cleanup_complete():
return True
E. Memory
Let’s now give our agent short-term memory, so it can reflect, remember, and avoid acting like a goldfish which keeps forgetting what its doing every few seconds.
Here’s a simple table explaining the memory states we would need (for this specific agent)
Memory Slots
| Slot | Purpose |
|---|---|
action_log |
Full list of actions taken so far (with timestamps) |
failures |
Actions that failed (with reasons) |
already_seen_files |
Prevent loops or unnecessary reprocessing |
reasoning_log |
LLM thoughts or intermediate plans |
user_feedback |
Human-in-the-loop approvals or corrections |
In the case for this simple agent, we can use a setup like this:
agent_memory = {
"action_log": [],
"failures": [],
"seen_files": set(),
}
As our loop runs,
def execute(action):
try:
run(action)
agent_memory["action_log"].append(action)
except Exception as e:
agent_memory["failures"].append({"action": action, "error": str(e)})
The memory passed into the following prompts would look like:
current_memory.txt
Here are the actions already taken:
[move_file(...), delete_file(...)]
Here are failed actions:
[delete_file("important.docx") → PermissionError]
We append this to our original prompt. We would do agent_prompt.txt + current_memory.txt. Something like this:
# build memory string
memory_str = build_memory_string(agent_memory)
# combine with static prompt
final_prompt = base_prompt + "\n\n" + memory_str
# send to LLM
response = call_llm(final_prompt)
This part is the absolute core of the agent - we stitched together a small hippocampus.
Let’s imagine what would happen without this part.
Say suppose the agent’s thoughts are:
- Iteration 1: LLM thought: “move file to
Finance”
But there’s no subdir named Finance. It should be calling a mkdir Finance but if it has no short term memory it won’t ever be able to do that.
It’s going to be like:
- Iteration 2: LLM thought: “move file to
Finance” - Iteration 3: LLM thought: “move file to
Finance”
It’s stuck in a loop.
With this dynamic memory injection, we’ll get something like the following:
Tried to move file to
Finance, operation failed. Logs returnedmv: cannot move 'image.jpg' to '/Finance/image.jpg': No such file or directory.
We can also create and add a summary of past actions to help the model more. The more context we give it the better it’ll perform - but there’s a tradeoff. Injecting too much memory will burn your compute and you will definitely start to see token drift.
Summary of past actions:
- 14 files moved
- 3 deletes
- 2 folder creation errors
We could’ve used a vector database like Pinecone but it’s definitely overkill for this situation because text-based memory injection gets us 90% of the way there with 0% of the infra overhead. However, if we did want to use a vector DB, our log-based text memories could be embedded into a latent space (via OpenAI embeddings, SentenceTransformers, etc.), allowing similarity search over past actions, reflections, or failures.
F. Planning tricks
We’ve now got the bare bones of the agent working but we can take advantage of some properties of LLMs to make our agent even smarter and efficient.
We’re now asking “How can my agent think better? How do I make it smarter at planning and sequencing actions?”
1) Chain-of-Thought Reasoning (CoT)
This is the core engine behind advanced models like OpenAI’s o-series (o1, o3, o4) though they implement it slightly differently in LLMs. For our case with our agent, we are going to force the LLM to think step by step before giving actions. This is going to help the LLM avoid impulsive plans and gives the model time to reflect.
We can prompt like this
Before you give the final plan, explain your reasoning step-by-step.
Example:
- I see Screenshot.png → this is likely an image → should go in Images/
- I see Invoice.pdf → sounds like financial doc → should go in Finance/
- temp_file.tmp → temp files can be deleted
Now we can tell it to return the final action list and we can expect a cleaner, distilled answer.
2) Reflexion Loop
The agent reflects on failed steps or suboptimal plans and tries again.
We can add the following
Previous plan caused an error: `move_file(...) → No such folder`.
Reflect on why that happened and propose a corrected version.
to tell the model to try again and improve it’s reasoning.
This builds resiliance into the model because it now knows what works and doesn’t work.
3) Tool Conditioning
We have to be very explicit about which tools (actions) can be used and when; in the earlier section I gave an example that an agent could call os.system("rm -rf /") at the root if it didn’t have protection layers. In real world and production settings we have tons of tools that we want to give to the agents, but we want a lot of security about what they use when.
A simple example could look like this
Only use `move_file()` after confirming the destination folder exists.
Use `create_folder()` as a prerequisite.
Something like this can fix the hallucination of calling move_file() over and over again.
4) Dry Run Planning
Here we let the LLM just plan and think about its action steps before it actually goes ahead and takes actions. We can instruct as “Pretend this is a dry run. What would you do, and why?” This makes it verbose and cautious and is really useful for logging & debugging.
5) Self Evaluation Prompts
We can add
Evaluate the quality of this plan on a scale of 1 to 10.
Can you improve it before proceeding?
Sometimes this leads to better, safer plans — without extra compute on our end.
6) Planning Format Constraints
This might be the most important part of your agent. We would absolutely need the LLM to return its steps in the right format since we would just use a reader to go ahead and iterate through the scratch pad and do the actions one at a time. Incorrect formatting, even if it does have the correct information, may completely destroy the action taking part.
Here is what we can add to counter that
Return your plan in the form of a list of function calls:
[
create_folder("Images"),
move_file("Screenshot.png", "Images/"),
delete_file("temp.log")
]
G. Error handling
Some of the external calls from the agents will break, it’s inevitable because of the way things for in software. We need fallback logic for it to keep working around the issues that arise.
A few examples could be
- External web API fails? Check status code and retry or ask human for help.
- Model says nonsense? Add validation/parsing checks.
- Token limits? Summarize old context while keeping the most important parts and feed that into a new conversation.
Agents without error handling quickly fall apart after 1-2 steps.
H. Human-in-the-loop
Just like any machine learning pipeline, we would need to let a person intervene when confidence is low.
This is useful when:
- Stakes are high (money, production code)
- Ambiguity is high (fuzzy goals)
- You’re still testing your agent
This can be as simple as “do you want to approve this plan?” or “here are 3 options, pick one.” Setups like this are extremely useful in situations where the agent is working in high stakes environments where a single mistake could cost a lost.
2) Evaluating the Agent
Here are the core ways that agents are evaluated
- Mission Success Rate
- Dry Run Accuracy (Plan Quality Without Execution)
- Robustness & Recovery
- Format Compliance
- Memory Effectiveness
These metrics basically are your eval metrics (F1, accuracy) but now for the agent.
These metrics basically ask
“How smart is this agent, and how can we sharpen it for the next iteration?”
Your end goal should be to have an agent that shows signs of goal alignment, tool mastery, context awareness, and self-correction.
3) Guardrails, Retries & Safety Belts
Even the smartest agents make mistakes sometimes and that’s just the reality when we let stateless LLMs operate in the real world. There are a couple things that we can do to protect our agent from hallucinations, bad decisions, and fatal errors, kind of like doing pen-testing against your agent before you want to deploy it to production.
The main techniques are the following:
- Action Whitelist
We can hardcode a set of functions it’s allowed to call at a specific moment. If it tries to do something else, it will get rejected at the parser level.
ALLOWED_ACTIONS = {"move_file", "delete_file", "create_folder", ...}
This is the bare minimum safety net. As the agent becomes more powerful and scales up, the safety net must scale up sharply as well.
- Retry on Failure
LLMs hallucinate sometimes and external APIs flake sometimes. Retrying with feedback always helps.
- Tool Use Conditioning
Teaching the model when to use tools, not just how makes a huge impact. Models stop calling incorrect functions at the wrong time.
- Loop Protection
This prevents infinite cycles that go like the following
Move random.tmp to `/temp` → `/temp` doesn't exist → FAIL → Try again, move random.tmp to `/temp`
As you can see, FAIL is cycled over and over here.
By tracking seen files, failed actions, and planning we put a stop to this.
if action in memory["failures"] or file in memory["seen_files"]:
skip_action() # or if you have a specific prev_failed_action()
4) Scaling the Agent
Scaling an agent isn’t as simple as packing them into Docker containers and wiring them to K8s. The core question we are trying to hit on when we scale agents is:
“How do we scale these up across tasks, users, compute, and complexity?”
Here’s what we can do
1) Multiple Agents, Multiple Roles
Instead of one agent doing everything, we can create specialized agents
- Planner agent: break the main goal into subgoals with clarity
- File classifier agent: maps files to categories
- Executor agent: runs file system actions
- Logger agent: tracks state and reports summaries
We would have to use a message-passing loop (kind of like RabbitMQ) where agents would have to communicate through a shared memory or task queue.
This would essentially be like Kubernetes for reasoning tasks. Each pod (agent) has a role.
2) Scale Across Users
The main question we would have to solve is
What if 100 people wanted this agent we just built?
We would have to add
- User specific memory / namespaces
- Auth (if it’s a secure application, not just file system cleanup)
- A Flask / FastAPI wrapper to expose the agent
- A task queue like Celery to handle concurrent requests
3) Run in the Cloud
Cloud-scale will let your agent live persistently. We can
- Dockerize the whole thing
- Deploy on cheap VPS (Fly.io, EC2)
- Use AWS Lambda or Google Cloud Functions for tool execution
- Store memory in S3, Redis, Pinecone, or DynamoDB
This gives the agent the abilitiy to survive restarts, erorrs, and scaling needs for compute heavy tasks.
4) Parallelism and Streaming
Instead of waiting on one big LLM call → tool → repeat, we can:
- Parallelize tool cals (like gathering all metadata at once)
- Use async/await patters in Python (with
asyncio) - Stream LLM responses (like vLLM) for fast feedback
We can do something like this
metadata = await asyncio.gather(*[get_metadata(f) for f in files])
to lower latency for long sessions with a longer context window.
5) Agent as a Service
We can wrap the final agent into a full-on API other services (or other agents) can call.
We could expose endpoints like
/clean-up/analyze-docs/summarize-folder
if our own agent is fine tuned on that.
Adding rate-limiting and a proper API Gateway would now let other users plug in their own tools.
If you take a look, this method actually turned your agent into a microservice which makes it even more powerful (loose coupling, reusability across use cases, independent scaling, and deployment flexibility).
Conclusion
In my opinion, agents are really cool but they are super duck-taped. However, we’ve seen some great improvements come along the past 18 months and I have a lot of hope for this to scale up in the future. In fact a some people think that AGI = scaled-up, memory-rich, tool-using, autonomous agents stacked with reflection, planning, delegation, and self-improvement loops.
Please look at the accompanying repository to see the entire project. If you are interested in building your own agents, take a look at this plug and play repository of agentic tools I created.